Nos hemos mudado a github. Esta es documentación de una versión anterior. La última versión de la documentación se puede encontrar en https://tonib.github.io/lsigxextensions-docs/. El repositorio git con la última versión está en https://github.com/tonib/lsigxextensions/. Los binarios de todas las versiones se seguirán descargando de https://sourceforge.net/projects/lsigxextensions/files/
Crear un modelo
A continuación se explica como entrenar un model a partir de kbases propias.
Requisitos
- Python 3.8
- Tensorflow 2.5 instalado con un virtualenv
- Descargar los scripts de entrenamiento, disponibles en https://github.com/tonib/multihead-rnn-classifier
Una vez instalado esto, en la configuración, en los campos "Python virtualenv directory" y "Python prediction scripts dir.", hay que indicar donde se ha creado el virtualenv de Tensorflow y donde están los scripts de entrenamiento.
Proceso
Los pasos a seguir para crear el modelo son estos:
- Configurar los parametros del modelo
- Obtener ejemplos para entrenar el modelo. Estos ejemplos serán kbases existentes
- Entrenar el modelo
- Evaluar y probar el modelo
- Usar el modelo en producción
Todos los pasos, excepto el usar el modelo, se hacen desde el menu Lsi.Extensions > Tool Windows > Generate prediction model:
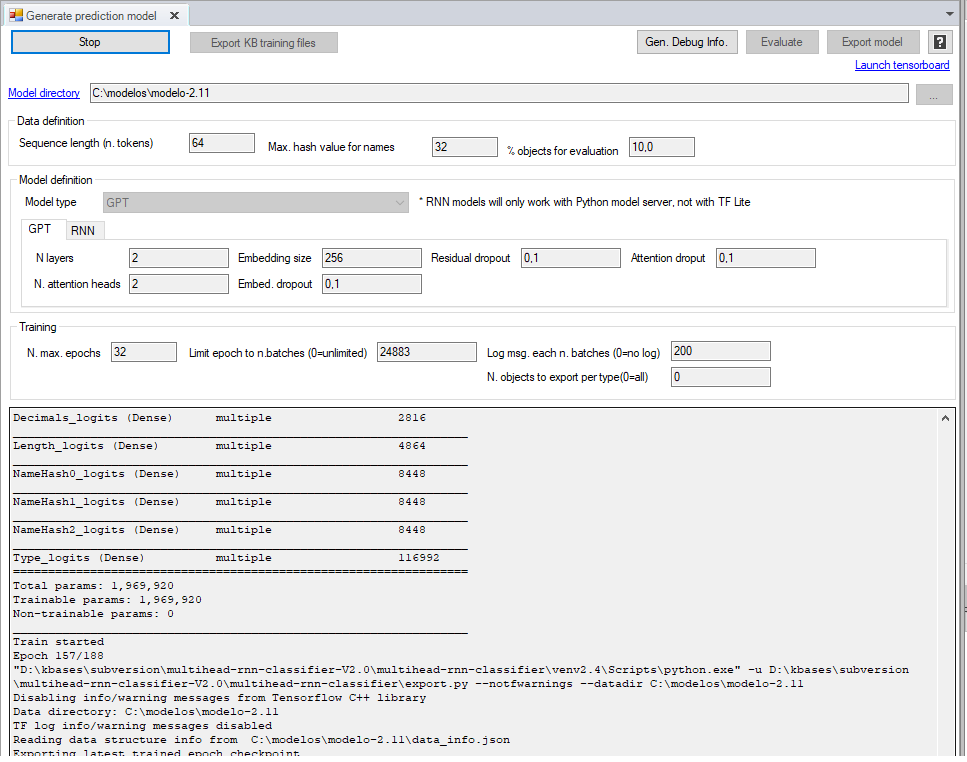
Configurar el modelo
En el formulario de la ventana de entrenamiento se configura como va a ser el modelo, y como se entrena. Los campos que definen como va a ser el modelo sólo se pueden indicar antes de obtener datos de entrenamiento, y despues no se pueden modificar.
A continuación se explican los campos:
| Model directory | Indica la carpeta donde se guardara el modelo y los datos de entrenamiento |
| Sequence length | Para predecir cual va a ser la siguiente palabra, se da como entrada al modelo la serie de palabras anteriores al cursor en el editor de código. Aquí se indica cuantas palabras previas como máximo se van a entrar al modelo. Cuanto mas grande es este número, más contexto tiene el modelo, y más lento (y grande) será el modelo. |
| Max. hash value for names | Indica el valor máximo que devolverá la función de hash que se utiliza para codificar el texto de las palabras (ver "Codificación del texto de las palabras") |
| % objects for evaluation | Para evaluar el modelo, normalmente se separa una parte de los datos de ejemplo, que no se usan para entrenarlo. Estos se usan para ver como de bien predice el modelo estos datos. Aquí se indica el porcentaje, de 0 a 100, de los datos que hay que usar para la evaluación. |
| Campos "Model definition" |
Estos campos definen la arquitectura y tamaño del modelo. El campo "Model type" indica el tipo de modelo: GPT o RNN. En caso de indicar
uno u otro, hay que ir a la pestaña con el mismo nombre y definir los parametros alli. |
| N. max. epochs | Una epoca es el entreno de todos los datos de ejemplo una vez. Dos epocas significa entrenar dos veces todos los datos. Aquí se indica cuantes veces entrenar los datos como máximo antes de parar el proceso. |
| Limit epoch to n. batches | Permite limitar una epoca a un número máximo de batches. Esto puede ser útil si se tiene un conjunto de datos de entrenamiento muy grande. Si se deja a cero, una epoca serán todos los datos de entrenamiento. Si se indica un número mayor que cero, una epoca se limita a este número de batches, elegidos aleatoriamente. |
| Log each n. batches | Si se indica un número, el proceso emitirá un mensaje de log en la salida indicando el estado del entrenamiento, cada cierto número de batches entrenados. Puede ser útil para saber como de rapido va el entrenamiento. Si se indica un cero, no se generará ningún log hasta que no se termine de entrenar una epoca. |
| N. objects to export per type | Al exportar los datos de entrenamiento de una kbase, permite limitar cuantos objetos de cada tipo (WebPanels, transacciones, etc) se exportarán. Puede ser útil para hacer pruebas. Si se deja a cero, se exportarán todos los objetos de la kbase. |
Hay un parametro importante, y que no es configurable, y es el tamaño de batch, que es de 64.
Los valores indicados en este formulario se guardarán al hacer la exportación de datos de entreno de la primera kbase. Tras esto, muchos de los valores ya no se pueden cambiar. Estas definiciones se guardan en un fichero "data_info.json" en la carpeta del modelo.
Obtener datos de entrenamiento
Una vez definidos los parametros del modelo, hay que exportar datos de entrenamiento de una o más kbases. Las kbases pueden ser de distintas versiones de Genexus, siempre que se tenga la misma versión (equivalente) de las extensiones en todas las versiones de Genexus.
El proceso es, para cada kbase, abrirla con Genexus, ir a la ventana de entrenamiento, asegurarse de que el campo "Model directory" (y los parámetros del modelo están indicados), y pulsar el botón "Export KB training files". Esto creará una carpeta para la kbase en el "Model directory", con los datos de entrenamiento de los objetos de la kbase, en formato CSV.
Es importante indicar que una vez se ha empezado a entrenar el modelo no se pueden exportar más kbases: TODAS las kbases de ejemplo han de estar exportadas ANTES de empezar a entrenar.
Entrenar el modelo
Una vez se han exportado todas las kbases, el proceso de entrenamiento se inicia indicando el campo "Model directory", asegurandose que los parametros estén correctos y pulsando el botón "Train new model". El proceso de entrenamiento se parará automáticamente al entrenar el nº de epocas indicado en "N. max. epochs".
El proceso de entrenamiento se puede parar y reanudar tantas veces como haga falta. Para pararlo hay que pulsar "Stop". Para reanudarlo, hay que indicar el campo "Model directory", y pulsar el botón "Continue training". Hay que tener en cuenta que el parar el entrenamiento puede tardar un poco
Si se va a parar el entrenamiento, hay que tener en cuenta que el progreso del entrenamiento se guarda al finalizar cada epoca. Esto significa que el progreso de entreanimiento de la epoca que se estaba entrenando actualmente se va a perder. Por esto, si el conjunto de datos de entremiento es muy grande, puede ser útil establecer el parametro "Limit epoch to n. batches".
El proceso guarda la información del modelo en la carpeta "model" del directorio del modelo. Al parar el entrenamiento, ya sea con el botón "Stop" o porque se ha llegado al nº máximo de epocas, el modelo se exporta en un formato usable por Tensorflow y Tensorflow Lite. Hay que tener en cuenta que se exporta la última epoca completamente entrenada: Si se parar el entrenamiento con el botón "Stop" en medio de un entreno, se pierde el progreso de entrenamiento de epoca qu estaba a medias.
El modelo Tensorflow exportado guarda en "model\exported_model" en la carpeta del modelo, y el modelo Tensorflow Lite se guarda en "model\model.tflite"
Evaluar y probar el modelo
Mientras el modelo se está entrenando, se escriben mensajes de log en el campo en la parte inferior de la ventana. Al finalizar cada epoca se muestra un mensaje de log con la evaluación del modelo, y, si se ha indicado el campo "Log msg. each. n. batches", se mostrarán mensajes con el estado del entrenamiento.
En la parte superior derecha de la ventana hay un link "Launch tensorboard" que lanzará Tensorboard, donde se puede consultar detalles del entrenamiento.
Una vez parado el entrenamiento, se puede probar el modelo con Genexus. Para indicar que se use este modelo, hay que ir a la configuración, en Autocomplete y en el campo "Use prediction model" indicar "Use custom TF Lite model" o "Use Python TF model". La primera opción usará Tensorflow Lite y la segunda usará Tensorflow para servir el modelo. En el campo "Custom model directory path" hay que indicar la carpeta del modelo (la misma que se indica en el campo "Model directory").
La opción "Use custom TF Lite model" es la recomendada porque es mucho más ligera, y no requiere tener instalado Python ni Tensorflow (una dll compilada de Tensorflow Lite se distribuye con las extensiones). Sin embargo, actualmente los modelos RNN no están soportados con Tensorflow Lite (GPT si). Asi que, si se indicó usar un modelo RNN sólo se puede usar "Use Python TF model". Esto requiere tener Python y Tensorflow instalados.
Una vez configurado esto, al escribir código en Genexus ya se usará el nuevo modelo. Se puede mostrar información de debug marcando "Debug prediction model" en la configuración > Autocomplete.
Usar el modelo en producción
Una vez se ha terminado de entrenar el modelo ya se puede usar en producción: El modelo exportado para producción se encuentran en la carpeta "model" del directorio del modelo, aunque muchos de ellos no se necesitan en producción. Los ficheros a distribuir del modelo para la producción dependen del si se va a usar Tensorflow o Tensorflow Lite para hacer las predicciones.
Si se va a usar Tensorflow Lite, la carpeta de producción ha de mantener al menos estos ficheros, con esta estructura:
[raiz del modelo]\
data_info.json
model_version.txt
model\
model.tflite
Si se va a usar Tensorflow, la carpeta de producción ha de mantener estos:
[raiz del modelo]\
data_info.json
model_version.txt
model\
exported_model\
[Todos los ficheros incluidos en la carpeta "exported_model"]
Hay que recordar que el modelo GPT se pueden usar tanto con Tensorflow como con Tensorflow Lite. Sin embargo, el modelo RNN solo se podrá usar con Tensorflow.
Si las predicciones se van a hacer con Tensorflow Lite, en los equipos que quieran usar el nuevo modelo no hay que instalar nada. Sólo hay que ir a la configuración > Autocomplete, indicar "Use prediction model" = "Use custom TF Lite model" y en "Custom model directory path" indicar donde esta la carpeta del modelo de producción.
Si las predicciones se van a hacer con Tensorflow, es más complicado. En el equipo que quiera usar la producción hay que instalar los mismos requisitos que para entrenar un modelo, configurarlos como si se fuera a generar un modelo en dicho equipo, poner "Use prediction model" = "Use Python TF model"y en "Custom model directory path" indicar donde esta la carpeta del modelo de producción.